ظهور علوم و فناوریهای نوین همواره با چالشهای جدیدی به همراه است. فناوریهای نوظهور از طرفی امور روزمره را تسریع میکنند و از طرف دیگر مشکلات جدیدی را ایجاد میکنند که پیشتر وجود نداشتند. با توجه بهسرعت پیشرفت فناوریهای امروزی، تغییرات و بهروز رسانی استانداردها و قوانین نیز با سرعت بیشتری باید انجام پذیرد. در این میان تبیین اخلاق و ارزشهای اخلاقی متناسب با حرفههای جدید سنگ بنای ایجاد استانداردها و قوانین است و از اهمیت فوقالعاده ویژهای برخوردار است.
علم داده و یادگیری ماشین از علوم جدیدی هستند که علیرغم رشد بسیار سریع در محیطهای دانشگاهی بهشدت در زندگی روزمره نیز کاربرد یافتهاند. یادگیری ماشین شاخهای از هوش مصنوعی است که کاربردهای وسیعی در علم داده و تصمیمات دادهمحور دارد. حجم دادههای جهان در سال 2020، نزدیک به 50 تریلیون گیگابایت است و پیشبینی میشود که این میزان در سال 2025 به 175 تریلیون گیگابایت برسد. حجم بازار دادههای بزرگ در جهان در سال 2020 نزدیک به 50 میلیارد دلار است که با کل بودجهی جمهوری اسلامی ایران قابل مقایسه است.
علم داده و یادگیری ماشین از جذابترین شغلهای قرن 21ام شمرده میشود. میانگین درآمد یک دانشمند داده در ایالات متحدهی آمریکا نزدیک به 110 هزار دلار است که رقمی بالا محسوب میشود. این حقوق بالا به معنای اهمیت فراوان علم داده برای کسبوکارها و کمبود متخصصان کافی در این زمینه است. بهمنظور تربیت متخصصان حرفهای و تزریق آنها به بازار کار، دانشگاههای معروف بسیاری در سراسر جهان در حال ایجاد گروهها و دانشکدههای علم داده هستند و در مقاطع کارشناسی ارشد و دکتری دانشجو جذب میکنند. در جمهوری اسلامی ایران نیز دانشگاههایی مانند دانشگاه شهید بهشتی و دانشگاه خاتم برنامههای علم داده را طرحریزی کردهاند. تعداد مقالات منتشر شده با کلیدواژهی علم داده، از سال 2013 رشد چشمگیری داشته است که نشانگر همهگیری این علم در دانشگاههای جهان است.
همانطوری که اشاره شد، امروزه در شرایط خاصی در علم داده هستیم. دادههای دقیق در حوزههای متنوعی در دسترس هستند و با گذشت زمان میزان و نوع دادهها در حال افزایش است. فناوریهای تحلیل داده رشد کردهاند و الگوریتمهای یادگیری ماشین مبتنی بر دادهها، برای پیشبینی پدیدههای مختلف مورد استفاده قرار میگیرند. در حال حاضر هیچ حدی برای کاربردهای وسیع علم داده وجود ندارد
. سؤالی که مطرح میشود این است که آیا، با توجه به وضعیت کنونی علم داده، آیا ما (انسانها و کسبوکارها) مجاز هستیم که هر کاری انجام دهیم؟ آیا جامعه میتواند در مورد محدودیت کاربرد علم داده در برخی زمینهها به توافق برسد؟
کاربرد علم داده در صنایع و تجارتهای امروزی بر کسی پوشیده نیست. در این میان وجود چارچوب اخلاقی برای علم داده و نحوهی استفادهی اخلاقی از دادهها مسئلهای است که میتواند زندگی میلیونها انسان را تحت تأثیر قرار دهد. علیرغم مفید بودن علم داده، این علم در صورت مشخص نبودن چارچوبی اخلاقی میتواند اثرات مخرب و جبرانناپذیری برای افراد و جوامع داشته باشد.
به علت جدید بودن علم داده، چارچوب اخلاقی آن در حال حاضر بهصورت کاملاً دقیق نمیتواند مشخص شود. بنابراین ابتدا نیاز است، که نمونههای پیشین کاربست علم داده که منجر به ظهور مسائل اخلاقی برای افراد و جوامع شده است؛ تحلیل و بررسی شوند. گسترش سریع کاربست علم داده در حوزههای گوناگون اجتماعی، مسائل اخلاقی این حوزه را بسیار پویا میکند. زمانی که هرزنامهها برای اولین بار در آمریکا ابداع شدند، کسانی که هرزنامهها را ابداع کرده بودند آن را یک روش بسیار هوشمندانه برای کسبوکارها دانستند و ابداع خود را یک افتخار میشمردند. اما با گذشت زمان و افزایش حجم هرزنامهها، این مسئله بسیاری از دریافتکنندگان را ناراضی کرد و امروزه ارسال هرزنامه نه تنها مایهی افتخار نیست که عملی غیراخلاقی و آزاردهنده شمرده میشود. بنابراین، قضاوت در مورد اخلاقی بودن در کاربست علم داده مسئلهای نیست که یک بار برای همیشه حل شود. مرزهای اخلاقی این حوزه با کسب تجارب بیشتر تغییر میکند و عملی که زمانی اخلاقی شمرده میشود پس از مدتی ممکن است غیراخلاقی شمرده شود و یا برعکس.
اخلاق همانند قانون نیست که الزامآور باشد، اما قوانین جامعه معمولاً بر پایهی اخلاق شکل میگیرند. بنابراین برای تدوین قوانین مناسب در حوزهی کاربرد علم داده، نیاز است که اخلاق علم داده بررسی شود، مسائل اخلاقی که در این حوزه در ایران و جهان اتفاق افتادهاند بررسی شوند و جنبههای مثبت و منفی کاربست علم داده در زندگی انسانها دقیقتر و کاملتر مشخص شوند. نتایج تحقیقات پیرامون اخلاق علم داده، مواد اولیهی بسیار مناسبی برای قانونگذاری در این حوزهی جدید در اختیار قانونگذاران میتواند قرار دهد.
امروزه رباتهایی که بر مبنای الگوریتمهای یادگیری ماشین طراحی شدهاند، بهعنوان دستیار قاضی، دستیار پزشک و یا در عملیات نظامی مورد استفاده قرار میگیرند. استفاده از این رباتها سرعت ما در تصمیمگیری افزایش میدهند. اما باید توجه کرد که این الگوریتمها بر مبنای دادههایی که به آنها بهعنوان ورودی داده شده است، کار میکنند و این مسئله میتواند منجر به تصمیمگیریهایی توسط این الگوریتمها شود که از نظر اخلاقی قابل پذیرش نیست. بهعنوان مثال، در ایالات متحدهی آمریکا، نسبت سیاهپوستان زندانی به سفیدپوستان زندانی بیشتر است در حالی که در کل جامعه آمریکا تعداد سفیدپوستان بیشتر از سیاهپوستان است. در الگوریتمهای یادگیری ماشین با دادن ویژگیهای اشخاص مانند رنگ پوست، قد، میزان تحصیلات، میزان درآمد و ... میتوان مدلی ساخت که احتمال مجرم بودن یک فرد را تشخیص دهد و بهعنوان کمک قاضی مورد استفاده قرار گیرد. نکته اینجاست که این الگوریتمها بر مبنای دادههای پیشین یاد میگیرند و بنابراین با توجه به دادههای موجود ممکن است مدلی به دست آید که سیاهپوست بودن را بهعنوان یک ویژگی تأثیرگذار در مجرم بودن قرار دهد. چنین مدلی از نظر اخلاقی قابل پذیرش نیست چراکه قضاوت آن نژادپرستانه است.
برخی از متخصصان علم داده، نتایج قضاوتهای علم داده در مورد انسانها را بدون سوگیری و کاملاً بیطرفانه میدانند چراکه دادهها عواطف و تعصبات انسانی را ندارند. اما سؤالی که مطرح میشود این است که اگر فرآیندهای علم داده و یادگیری ماشین سوگیری ندارند، پس چرا خروجیهای آنها همان سوگیریهایی را گاهی دارند که در جوامع انسانی وجود دارد؟ به عقیده کتی اونیل
[1]، فارغالتحصیل ریاضی دانشگاه هاروارد که متخصص علم داده و نویسندهی کتابهای اخلاقی در علم داده است، الگوریتمهای یادگیری ماشین به این دلیل همان سوگیریهای انسانی را دارند که با همان سوگیریها آموزش میبینند. به عقیدهی وی، متخصصان علم داده و مهندسان یادگیری ماشین، با استفاده از واژهی «مدلهای یادگیری ماشین» و معرفی آن بهعنوان یک جعبه سیاه، از مسئولیت خود در نتایج حاصل از این الگوریتمها سرباز میزنند. درست است که الگوریتمهای یادگیری ماشین بهطور مستقیم برنامهنویسی نمیشوند و بر مبنای دادهها خود شروع به تشخیص و یادگیری میکنند اما باید توجه داشت که انتخاب اینکه چه دادههایی بهعنوان ورودی به الگوریتم داده شود، انتخابی است که انسانها اختیار میکنند. کتی اونیل معتقد است که سلاحهای ریاضی امروزه خرابیهای را به بار میآورند که نه ناشی از خود آنها بلکه ناشی از سازندگان آنهاست. متخصصان علم داده، سبب میشوند که الگوریتمها سوگیری داشته باشند به این دلیل که موقع انتخاب دادهها به اندازهی کافی به مسائل اخلاقی و انسانی توجه ندارند. بنابراین مسائل اخلاقی که در ماشینها بروز میکند، ناشی از مسائل اخلاقی است که متخصصان علم داده به آنها توجه کافی ندارند.
نکتهی مهم دیگر، پویا بودن مسائل اخلاقی در زمینهی علم داده است. عملی که امروزه با استفاده از دادهها اخلاقی است ممکن است در سالهای بعدی غیراخلاقی و حتی مجرمانه محسوب شود. هرزنامه نمونهی جالبی برای تبیین این مطلب است.
در سالهای 1990 که اینترنت بهتازگی برای مقاصد تجاری مورد استفاده قرار گرفته بود، کسبوکارها به دنبال یافتن راههایی برای کسب درآمد بیشتر بودند. در آوریل سال 1994 لورنس سنتر
[2] و مارتا سیگل
[3] دو وکیل از شهر فینیکس
[4] در ایالت آریزونا
[5]، یک برنامهنویس را استخدام کردند تا پیام قرعهکشی کارت سبز
[6] را به هرچند جا که میتوانند بهصورت الکترونیکی پست کنند. آنها این نکته را مخفی نکردند، و به روش تبلیغاتی خود افتخار کردند و حتی کتابی نیز دربارهی استفاده از دنیای جدید اینترنت برای بازاریابی منتشر کردند. ایمیلهایی که آنها ارسال کردند، نمونهای از ایمیلهایی است که امروزه به آنها هرزنامه گفته میشود. هرزنامه عبارت است از ایمیلی که برای گیرندهی نامه ناخواسته
[7] است و بهصورت گروهی به آدرسهای مختلفی فرستاده میشود. در زمانی که سنتر و سیگل هرزنامه ارسال کردند، آن هرزنامه بهعنوان یک ایدهی جدید که از بستر اینترنت استفاده میکرد مورد ستایش واقع شد. اما با گذشت زمان که تعداد هرزنامهها افزایش یافت، ارسال هرزنامه سبب نارضایتی و اسباب زحمت دریافتکنندگان شد زیرا آنها مجبور به تفکیک بین هرزنامه و نامههای ضروری شدند. به عبارت دیگر، هرچند در سال 1994 ارسال هرزنامه غیراخلاقی به نظر نمیرسید، اما به مرور زمان و با آشکار شدن اثرات مخرب هرزنامهها، ارسال هرزنامه کاری غیراخلاقی شمرده شد. در سال 2003 کنگرهی ایالات متحده قوانین ضد هرزنامه را به تصویب رساند. علیرغم تصویب این قوانین، امروزه نیز هرزنامهها فراوان هستند، اما ارسالکنندگان هرزنامه حتی در صورت موفقیت، به کار خود افتخار نمیکنند و کتابی در آن مورد انتشار نمیدهند، زیرا امروزه ارسال هرزنامه عملی غیراخلاقی محسوب میشود.
مالکیت داده از مباحث مهم دیگری است که باید مورد توجه قرار گیرد. زمانی که شخصی یا شرکتی دادهای را در مورد مشتریهای خود جمعآوری میکند، چه کسی مالک دادههای جمعآوریشده است؟ از طرفی دادهها در مورد مشتریها هستند، اما از طرفی جمعآوری و سازماندهی دادهها کاری هزینهبر است و جمعآوریکنندهی داده مستحق تشویق است. در حال حاضر، عقیدهی پذیرفتهشده در مورد مالکیت داده آن است که جمعآوریکنندهی داده در جمعآوری داده از اشخاص باید قیود اخلاقی پذیرفته شده مانند احترام به حریم خصوصی و ارزشهای اجتماعی را رعایت کند؛ اما دادههایی که با رعایت این قیود جمعآوری میشوند جزو داراییهای جمعآوریکننده هستند هرچند که در مورد اشخاص دیگری باشد.
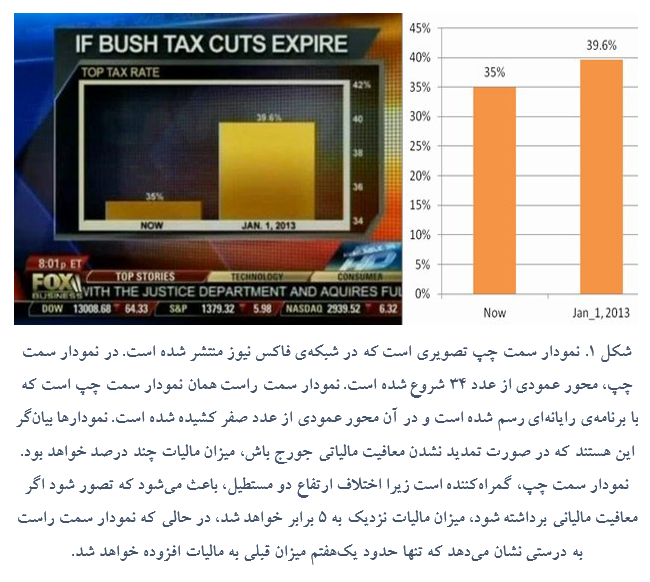
مطلب دیگری که در مورد استفاده از داده وجود دارد اعتبار داده و فرآیند علم داده است. استفاده از دادههای مناسب و انجام فرآیندهای صحیح و اعلام نتایج معتبر در علم داده باید رعایت شوند. استفادهی نامناسب از ابزارهای علم داده میتواند نتایج غیر صحیحی را عمدی یا سهوی در جامعه به بار آورد. در شکل 1، تصویری از شبکه فاکس نیوز، شبکه تلویزیونی جمهوری خواهان در آمریکا، نشان داده شده است که میزان افزایش مالیاتها در صورت حذف معافیت مالیاتی جورج بوش چه قدر خواهد بود. شبکه فاکس نیوز محورها را از عددی نامناسب رسم کرده است و به نظر میآید میزان مالیاتها چندین برابر خواهد شد، در حالی که واقعیت چنین نیست. این نوع ارائهی نتایج مبتنی بر داده، به مقاصد فریبکارانه غیراخلاقی است و تأثیرات سرنوشتسازی در جوامع میگذارد. آشنایی با نحوهی اعتبارسنجی دادهها جهت آشنایی با اقدامات غیراخلاقی ضروری است.
ممکن است اینگونه به نظر برسد که علم داده در کشورهایی آمریکای شمالی و اروپا بیشتر استفاده میشود و مدت زمان زیادی طول خواهد کشید تا علم داد در کسبوکارهای ایرانی مورد استفاده قرار گیرد و بنابراین صحبت از اخلاق علم داده در کشور کمی زود است. باید توجه کرد که این طرز تفکر صحیح نیست. در حال حاضر بسیاری از کسبوکارهای داخل ایران همانند کافه بازار، آپارات، دیجی کالا، تپسی و ... هماکنون دارای گروههای تحلیل داده هستند و برای رونق کسبوکار خود از نتایج کاربست علم داده استفاده میکنند. بنابراین مشکلات اخلاقی علم داده در کشور ایران نیز وجود دارند و بحثهای اخلاقی علم داده در داخل کشور بسیار حائز اهمیت هستند. بررسی مسائل اخلاقی علم داده در خارج از کشور و انتقال تجارب کسبشده به کسبوکارهای داخل کشور، در رویارویی کسبوکارهای داخلی با این نوع مسائل بسیار مفید میتواند باشد.
با توجه به آنچه گفته شد، با ظهور علم داده و یادگیری ماشین و جایگزین شدن الگوریتمهای هوش مصنوعی با انسان در انجام وظایفی که قبلاً توسط انسان انجام میشد، سؤالات اخلاقی جدیدی مطرح شدهاند. برخی سؤالهایی که ایجاد شدهاند عبارتاند از:
- سوءاستفاده از داده به چه معناست و راه مقابله با آن چیست؟
- چگونه میتوان حریم شخصی را در استفاده از داده رعایت کرد و در عین حال خدمات مناسب به افراد را بر اساس دادهها ارائه داد؟
- چگونه میتوان از غرضورزی در انتخاب داده جلوگیری کرد؟
- چگونه میتوان از حمله به داده و خراب کردن آن جلوگیری کرد؟
- مالکیت دادهها با چه کسانی است؟ چه کسانی و تحت چه شرایطی میتوانند به دادهها دسترسی داشته باشند؟
- چه مقدار از دادههای مربوط به یک فرد توسط فرد دیگر یا یک سازمان باید جمعآوری شود؟
- اگر بر اساس الگوریتمهای یادگیری ماشین تصمیمی گرفته شود، مسئولیت عواقب آن تصمیم با چه کسی است؟
این سؤالها و سؤالات دیگر بسیاری نیاز به پاسخگویی دارند و در حال حاضر اتفاق نظری در مورد جواب به این سؤالات وجود ندارد. تلاش برای دقیقتر و جزئیتر کردن این سؤالها و درنهایت پاسخ به آنها چارچوب مناسبی بر اخلاقی رفتار کردن در عصر علم داده و استفادهی اخلاقی از علم داده و یادگیری ماشین را فراهم خواهد کرد. پژوهشگاه فضای مجازی در راستای اهداف خود، پروژهای در این راستا تعریف کرده است که خروجی اصلی آن کتابی با عنوان «اخلاق علم داده» خواهد. در این کتاب، با استفاده از مثالهای متنوع، پیامدهای استفاده از علم داده در حوزههای مختلف زندگی انسانها بررسی خواهد شد.
نگارنده: دکتر جواد عبادی (دکتری فیزیک ذرات پژوهشگاه (IPM
تهیه شده در گروه مطالعات اخلاقی پژوهشگاه فضای مجازی
[6] کارت سبز یا گرین کارت به کارتی گفته میشود که نشاندهنده اقامت دائم در ایالات متحده آمریکا است.









 نظر کاربران
نظر کاربران
